組んだPCのメモ
家でVR ChatやFPS系のゲームをやりたくてPCを組んだ。ゲームの方はあまりやるこんだりする予定ではない。 このあたりの記事やゲームの推奨スペックなどを参考にしてパーツを選んだ。
グラボ
ASUS NVIDIA GEFORCE RTX 2070 SUPER 搭載 トリプルファンモデル 8G ROG-STRIX-RTX2070S-A8G-GAMING
CPU
ASRock AMD Ryzen AM4 対応 B450 チップセット搭載 ATX マザーボード B450 Steel Legend
cpuに対応しているチップセットから絞っていった
SSD Samsung 970 EVO Plus 500GB PCIe NVMe M.2 (2280) 内蔵 SSD MZ-V7S500B/EC 国内正規保証品
m.2 nvmeを探した www.amazon.co.jp
メモリ
CORSAIR DDR4 デスクトップPC用 メモリモジュール VENGEANCE LPX Series 16GB×2枚
電源
ANTEC アンテック 80PLUS BRONZE認証電源 ANTEC アンテック NeoECO Classicシリーズ 650Wモデル
rtx2070 superの推奨電源ユニット容量 が 650 Wだったのでそこから絞った
ケース 静寂
windows 10 home
以下は購入したが使用しなかった。
CPUクーラー
虎徹 Mark-2
マザボにCPUクーラーが付いていたのでひとまずはそっちを使っている。
https://www.amazon.co.jp/gp/product/B072PWL5YF/ref=ppx_od_dt_b_asin_title_s02?ie=UTF8&psc=1
グリス
マザボについていたCPUクーラーにグリスがもともとついていたので、そちらを使用。
https://www.amazon.co.jp/gp/product/B011F7W3LU/ref=ppx_od_dt_b_asin_title_s02?ie=UTF8&psc=1
長尾製作所 M.2 SSD用ヒートシンク SS-M2S-HS01
マザボにM.2 SSD用のものが一つ付いていたのでそちらを使用。
https://www.amazon.co.jp/gp/product/B06XK3Z1RK/ref=ppx_od_dt_b_asin_title_s02?ie=UTF8&psc=1
x86_64のarch linuxにTrueSTUDIOをinstallする
室内用ドローン STEAVAL-DRONE01を購入し、開発環境の構築にTrueSTUIDOが必要だったのでarch linuxからinstallした。 あまり理解できていない部分もあるので、今後エラーが起きたときの備忘録として書き記す。 やり方を間違っている可能性もあるので、気づいたら書き直す。
TrueSTUIDOのversionは9.3.0
はじめはyayでinstallしようとしたが、installしたファイルの一部が破損していてうまくいかなかった。(あんまり良くわかってない。)
なので以下のページからinstallすることにした。 atollic.com
Requirements に
64-bit distribution with 32-bit C runtime libraries installed
とされていたが、自分の環境にはそれがなかったのでそこからinstallした。
まず64ビット環境で32ビットアプリケーションを実行できるようにするため、
ArchWikiのMultilibを見つつmultilibをinstallし、wiki上の有効化の手順を踏んだ。
wiki.archlinux.jp
そして、32-bit C runtime librariesにあたるlib32-gcc-libsをinstallした上でTrueSTUDIOをinstallした。
上記の手順でうまく行った。
Container Analysis APIを用いてコンテナイメージの脆弱性のSummaryのdataを取得する
目次
- Container Analysisの必要性
- Container Analysis APIの利用
- gcloud コマンドでうまくいかなかったことについて
- おわりに
Container Analysisの必要性
コンテナ イメージによって開発やデプロイはよりスムーズに行えるようになった。 それに伴いコンテナイメージ内のOSに対する脆弱性にも注意深くなる必要がある。
GCPでは Container Analysisという機能があり、Container Registry 内のコンテナ イメージをScanし脆弱性を検知してくれる。
https://cloud.google.com/container-registry/docs/container-analysis?hl=ja (2019-10-28現在ではベータ版である。)
この機能を有効にするとCloud ConsoleのContainer Registryのページから検知された脆弱性を確認することができる。
また、Contanier Analysis のRest APIを利用してSummaryを取得することもできる。この記事ではそちらに焦点をあてたい。
Container Analysis APIの利用
Cloud Consoleで脆弱性の確認はできるものの、それだけでは毎回脆弱性の情報を拾いに行く必要が出てくる。 流石にそれだと面倒なので、定期的にそのdataをSlackにPostする仕組みを整えた。
以下具体的な説明だが、ここではSlackでごにょごにょする部分には触れずに、Container Analysis APIをどう利用したかのみを書く。
今回はContainer Registryのprojects.occurrences.getVulnerabilitySummaryのmethodを利用して脆弱性の情報を取得した。
初めはgcloud コマンドで取得するつもりでいたが、うまくいかなかったので断念した。それについては後ほど触れる。
実行したコマンドはこれ。
[RESOURCE_URL]はhttps://[HOSTNAME]/[PROJECT_ID]/[IMAGE_ID]@sha256:[HASH]を入れる。
curl -H "Authorization: Bearer $(gcloud auth print-access-token)" 'https://containeranalysis.googleapis.com/v1beta1/projects/{PROJECT_ID}/occurrences:vulnerabilitySummary?filter=resourceUrl%3D%22[RESOURCE_URL]%22'
そこで得たdataをjqを利用して加工、SlackへPostする。という流れ。
一応jqを利用した部分のスクリプトをメモしておく。
severityがHIGHな件数を取得するスクリプト
curl ....(同上) | jq -r ".counts[] | select(.severity == \"HIGH\" and .resource.name == \"[project名]\") | .totalCount")
2つ目が修正可能な件数を取得するもの。
curl ....(同上) | jq -r "[.counts[] | select(.resource.name == \"[project 名]\") | .fixableCount // 0 | tonumber] | add // 0")
gcloud コマンドでうまくいかなかったことについて
ドキュメントによると以下のようなgcloudコマンドでイメージの脆弱性の情報を取得できるとある。(2019-10-29時点)
gcloud beta container images list-tags --show-occurrences [HOSTNAME]/[PROJECT_ID]/[IMAGE_ID]
しかし、このコマンドによって得られた脆弱性の情報は Cloud Console上で確認できる脆弱性の情報と一致しなかった。 具体的に言うと脆弱性のレベルの内訳が一致していないかった。
調べた感じだと 単純にcvssから算出した 重大度とlinux distributionから指定された重大度があるようで、 Cloud Console上ではlinux distributionから指定された重大度を加味した情報が表示されている。その一方で、上記のgcloud コマンドでは それが加味されておらず、内訳が一致しなかった模様。
https://cloud.google.com/container-registry/docs/container-analysis(英語ページより)
Two types of severity are associated with each vulnerability:
- Effective severity - The severity level assigned by the Linux distribution. If distribution-specific severity levels are unavailable, Container Analysis uses the severity level assigned by the note provider.
- CVSS score- The Common Vulnerability Scoring System score and associated severity level. Refer to the CVSS 3 specificationfor details on how CVSS scores are calculated.
For a given vulnerability, the severity derived from a calculated CVSS score might not match the effective severity. Linux distributions that assign severity levels use their own criteria to assess the specific impacts of a vulnerability on their distributions.
おわりに
gcloudコマンドで欲しかった情報が取れなかったのは少しつらかった。 今はbeta版ということもあるので仕方はない部分もあるが、そのうちそのあたりは修正されていくのではと思う。
ラズパイに無線でsshするまでの雑なメモ
モデルはRaspberry Pi 3 Model B+
必要なもの - SDカード - 有線LAN
- SDカードにイメージを書き込む
- SDカード内のsshファイルを作成 (自分の場合は/run/media/
/boot) - ラズパイにsdカード挿して、有線でマシンとつなぐ
ssh pi@raspberrypi.localでログイン。パスワードはraspberrysudo raspi-configでsshをenableにする/etc/wpa_supplicant/wpa_supplicant.confにwifiのssidとpasswordを追加
wpa_supplicant.confに関しては、 sdカード内のboot directory直下にwpa_supplicant.confが存在すると起動時にマウントされるみたい。
その場合は有線LANもいらないかもしれない。
firebaseのコンソールからAuthenticationを登録しているアカウントを全て削除する
開発中に大量に作ったアカウントを消したい時画あると思う。
しかし、firebaseのAuthenticationは登録しているアカウント全てを削除する機能がない。
そこでDOMをいじって削除ボタンのクリックをiterateしてあげる。
stackoverflowからの引用にはなるが下にコードを残しておく。これをchrome consoleなどで実行すればいい。 日本語のUIにあわせている。 Delete all users from firebase auth console - Stack Overflow
var intervalId;
$('[aria-label="アカウントの削除"]')[0]
var clearFunction = function() {
if ($('[aria-label="アカウントの削除"]').size() == 0) {
console.log("interval cleared")
clearInterval(intervalId)
return
}
$('[aria-label="アカウントの削除"]')[0].click();
setTimeout(function () {
$(".md-raised:contains(削除)").click()
}, 1000);
};
intervalId = setInterval(clearFunction, 3000)
circleciでshallow cloneするとlocalでの実行時も快適になって良さそうだ
circleciではLocal CLIが提供されていて、導入時にいちいちpushしてjobを実行しないで済む。 circleci.com
circleciをローカルで実行できるのはいいが、プロジェクトをcloneするcheckoutのstepの実行には時間がかかるし、ローカルでは save_cacheやrestore_cacheは利用できないので割とつらい。
そこでcheckoutのstepを利用するのを諦め、shallow cloneを行う方向にした。 さらに嬉しいことにcircleciの v2.1ではジョブなどをパッケージ化して共有することができる orbsという機能がリリースされたらしく、探して見るとshallow cloneを提供している orbもいくつかあるので、自分で0からコードを書く必要もない。
僕は他の記事でも紹介されていたganta/git@1.2.0 を利用させていただいた。
https://circleci.com/orbs/registry/orb/ganta/git
この記事を書いている時点では まだしっかり本番運用などはしていないので、そのあたりの快適さには言及できない。
ローカルでの実行はかなり早くなったので、ひとまずセットアップ時だけ使うにしてもかなり楽になった。
細い説明はしないが、実際に使う時に注意することとしては
- v2.1のcircleciをローカルで実行するには、circleci config process .circleci/config.yml でv2.0にコンパイルしてから実行する必要があるということ。
- ssh keyが存在するdirecotryをcircleciで作成したコンテナにマウントする必要があるということ。
今のところはプロジェクトのルートで以下のコマンドを実行してローカルで動かしている。
circleci config process .circleci/config.yml > .circleci/tmp_config.yml && circleci local execute -c .circleci/tmp_config.yml --job build --volume ~/.ssh:/home/circleci/.ssh && rm .circleci/tmp_config.yml
質の高いコードレビューをするために考慮すべき視点の洗い出し
どうせするなら質の高いコードレビューがしたい。しかし自分のコードレビューは質が高いものには程遠い気がする。 そもそもコードレビューにはどういう視点が必要なのか。自分に何が足りないのか知るべく整理してみた。
コードレビューの目的
コードレビューの目的を分類すると以下の2つになるのではないかと思う。
- 品質を上げる
- 組織内で共通認識をつくる
品質を上げるためのコードレビュー
製品やコードの品質を保証するためには以下の5つの視点でのコードレビューが必要ではないだろうか
- 仕様
- 可読性
- パフォーマンス
- セキュリティ
- バグがでそうか
仕様
そもそも開発が正しい方向性に進めているのかは重要だ。 開発に着手する前にある程度の仕様は決まっているかとは思うが、開発を進めているとどこか仕様が抜け落ちていたりする。 それが意図的なものでも意図的でなくとも、それが正しいのかという客観的なレビューは必要である。
可読性
可読性が重要なことは言うまでも無いと思う。 具体的には以下のような視点が考えられる。ぱっと思いついたものを挙げてみた。
- 設計思想に沿っているか
- 依存関係が複雑でないか
- コードを書くべきところに書かれているか
- PRやコミットの粒度は適切か
- 肥大化していないか
- スタイルガイドに沿っているか
- 一貫性があるか
- 命名がわかりやすいか
- typoがないか
パフォーマンス
具体的な手法は書くと長くなるので書かないが(そもそも理解できているとは言い難い)、そのコードが製品の動作を遅くしないかという視点は重要である。
まだきちんと読んでないが、具体的にどういうこの記事が参考になるかもしれない。 https://blog.jetbrains.com/upsource/2015/08/06/what-to-look-for-in-a-code-review-performance/
セキュリティ
今の製品のフェーズに必要なレベルのセキュリティを満たせているかという視点は必要だ。
バグが出そうか
バグがあるかどうかを実際に自分の環境で全て確認するまではしなくて良い気がするが、 バグを出さないために適切なテストコードが書かれているかや、コードが複雑になってしまっていないかなどのチェックは必要だと思われる。 ここは可読性と被る部分もある。
組織内で共通認識をつくるためのコードレビュー
コードレビューを行う目的として組織内で共通認識をつくることを挙げた。 コードレビューでは製品に使っているライブラリ、スタイルガイド、細かな挙動の仕様などを共有できるというメリットもある。
そうすると開発チーム内での話も進みやすいし、自分が開発している時に一度レビューしたコードが参考になることを思い出すこともあるだろう。
ネガティブになりうる要因
品質の保証や共通認識をつくるのに必要とはいえ、コードレビューはネガティブな方向にも作用しうる。 具体的には以下のようなことがある。
- コードレビューのタスクに時間がかかり開発スピードが落ちる
- レビュワーとレビュイーでのコミュニケーションがうまくいかず疲弊する。
- レビューがたまり、心理的な負担が大きくなる。
このネガティブな要因をいかに克服するかも質の高いコードレビューをするために不可欠だろう。
おわりに
ここではざっくり考慮すべき視点を洗い出したが具体的にどういう知識が必要か、どういう策を講じるといいのかもおいおい考えていきたい。
sinonでNodeのprocess.envにbool値を定義してテスト
javascriptのテストを書く時に、環境変数であるprocess.envに値をセットしてテストした時があると思います。
そんな時、process.env.HOGE= 'HOGE'; のように文字列を代入する時には問題は起こらないのですが、process.env.FUGA = trueというように bool値を代入しようとすると問題が発生します。
それについて少しメモを残します。
何が起こるのか
Node.jsのドキュメントには以下のように書いてあります。
Assigning a property on process.env will implicitly convert the value to a string. This behavior is deprecated. Future versions of Node.js may throw an error when the value is not a string, number, or boolean.
https://nodejs.org/api/process.html#process_process_env
つまりはprocess.envとして定義した値はstringに変換される。ということです。 (This behavior is deprecated.... 以降の文から将来的にはnumberやbooleanを割り当てた時にどうなるのかは読み取れませんでした。)
このようなコードがあった時の挙動について少し説明を加えてみます。
if (process.env.HOGE) {
console.log('hoge')
}
このようなコードがあった時、test上で process.env.HOGE = false と定義したとしても process.env.HOGEの値は 'false' という文字列となり、process.env.HOGEの値は文字として存在することになります。
したがって、本来読み込まれてほしくないconsole.log('hoge') が読み込まれてしまう。という挙動になります。
開発環境での定義
注意する必要があることは、開発環境でもprocess.envの値が必ずしも文字列として定義されているわけではないということです。
僕はwebpackをよく使うのでwebpackでの説明に限定させてもらうのですが、webpackで環境変数を定義する時にはbooleanとして定義できてしまいます。 webpackでprocess.envの値をセットする時にはおそらくDefinePluginを利用することが多いかと思います。
こちらのプラグインでprocess.envを定義した際には、stringとしてもbooleanとしても定義できてしまいます。
したがって process.evn.HOGEの値は'true'ではなくtrue と定義されている可能性もあるのです。
個人的には、実際コードを書く時も、
if (process.env.HOGE === 'true') {
console.log('hoge')
}
のように書くよりも
if (process.env.HOGE) {
console.log('hoge')
}
というように書いてしまいたいです。なのでtestでも booleanとして定義できるようにするのが、僕にとっては最適でした。
sinonを利用してprocess.envを定義
このような時に利用できるのがsinonです
sinonでは、stubとして値を定義することができ、それはprocess.envにも適用できます。 詳しい使い方はドキュメントを見ていただくといいかと思います。
例えば、以下のようにすることで、booleanのHOGEをprocess.envにセットすることができます。
import sinon from 'sinon';
const sandbox = sinon.createSandbox();
sandbox.stub(process, 'env').value({ HOGE: true });
これで process.envにbool値を定義した上でテストを行うことが可能になります。
Firebaseを使ってsnsアプリでよくあるtimelineを実装する際に参考にした記事・スライド・リポジトリ
最近react-nativeでとあるアプリを開発しており、裏側ではfirebaseを利用しています。
SNSでよくあるtimelineの実装をして割と手こずったのですが、その時に参考にした記事やリポジトリをまとめておきます。 誰かの参考になれば幸いです。
GDG DevFest Tokyo 2018での発表
もうこれを見たら設計はほぼ大丈夫な気がします
firebaseの公式ドキュメント
GDG DevFesのスライドでも出てくるファンアウトについては、firebaseの公式ドキュメントに少し説明があります。
https://github.com/deltaepsilon/firebase-demos/tree/master/twitter-clone
はじめはコチラのリポジトリを参考にしていました。GDG DevFest Tokyoのスライドを見れば特に見る必要はないかもです。
https://github.com/kuy/redux-saga-examples/tree/master/microblog
僕はreduxのmiddlewareであるredux-sagaとfirebaseを利用しているリポジトリになります。 僕はredux-sagaを利用していたので少し参考にさせてもらいました。
React Nativeでsvgファイルを読み込んで表示する
react-nativeにおいてpngやjpgのファイルを表示させるにはこちらのFacebook Engineering Blogに書かれているようにImageコンポーネントをimportしてsource propertyでファイルを指定すれば可能なのですが、同じ方法でsvgファイルを表示させることはできません。
そこで利用するのが、react-native-svg-uriです。 これはexpoを利用している方も同じように使うことができます。
react-nativeのsvgに関するライブラリをググるとreact-native-svgもヒットすると思います。しかし、こちらはsvgのタグが利用できるようにはなるものの、svgファイルを読み込むことはできないようでした。
手順
まずライブラリをインストールします。
npm i react-native-svg-uri
そしてそれをimportし、SvgUriコンポーネントのsource propertyにファイルをrequireしたものを渡せばsvgが表示されます。 以下のようなイメージです。
import SvgUri from 'react-native-svg-uri';
const logoImage = require('../../assets/icons/logo-main.svg');
...<略>
// React component内のrenderメソッド
render() {
return(
<View>
<SvgUri source={logoImage} />
</View>
)
}
Visual Studio Codeを使ってC++でHello World
C++でhello worldする記事はたくさんあるんですが、VSCodeをあまり使い慣れておらず手間取ったのでまとめてみます。
今回はVSCodeはインストール済みという前提で説明させていただきます。 また、ここでは挙動についての詳細な説明はせず、VSCodeでHellow Worldすることのみにフォーカスします。
対象読者は以下の人を想定しています。
下準備
まずVSCodeを使ってC++で開発しやすいように拡張機能をインストールしましょう。
まず⌘+shift+xを押してみてください。以下のようなサイドメニューが表示されると思います。これは拡張機能ビューと呼ばれるもので拡張機能をインストールできる画面になります。
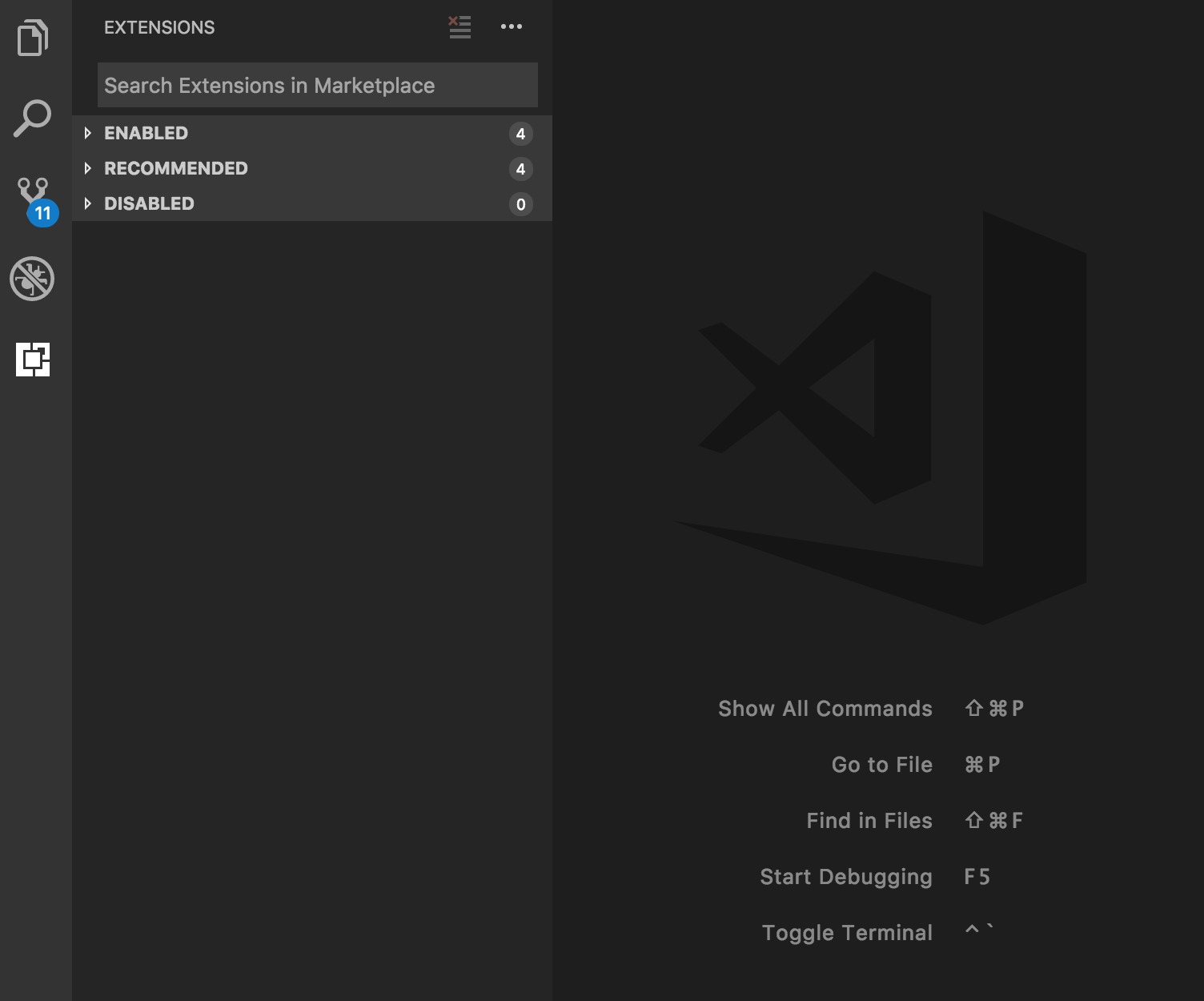
この画面にある検索フィールドにcpptoolsと入力しインストールした後にVSCodeをReloadしてください。
この拡張機能をインストールすることで自動補完や定義元へのジャンプなどが可能になるようです。
ファイル作成
次にhelloworld.cppというファイルを作成した後、以下のように記述します。
#include <iostream>
int main()
{
std::cout << "Hello C++ World" << std::endl;
return 0;
}
こいつをコンパイルして実行するとHello C++ Worldと表示されるはずです。
ではVSCodeでビルドしてきましょう
VSCodeでビルド
ファイルのコンパイルはターミナルでもできます。
その際には
g++ ~/helloworld.cpp -o helloworld.outみたいな感じでコンパイルできます。
まあVSCodeのショートカットキーでビルド可能なのでビルドはVSCodeに任せてしまいましょう。
VSCodeからビルドを行うためにまず、tasks.jsonファイルを作成する必要があります。以下の手順に従ってファイルを作成してください。
⌘+shift+Pでコマンドパレットを開くTasks: Configure Tasksを入力してEnterCreate tasks.json file from templatesを選択- 最後にOthers を選択
以上の手順が完了すると以下のようなtasks.jsonファイルが出現します。
{
// See https://go.microsoft.com/fwlink/?LinkId=733558
// for the documentation about the tasks.json format
"version": "2.0.0",
"tasks": [
{
"label": "echo",
"type": "shell",
"command": "echo Hello"
}
]
}
このファイルを次のように書き換えてみて下さい
{
// See https://go.microsoft.com/fwlink/?LinkId=733558
// for the documentation about the tasks.json format
"version": "2.0.0",
"tasks": [
{
"label": "build hello world",
"type": "shell",
"command": "g++",
"args": [
"-g", "-o", "${fileDirname}/${fileBasenameNoExtension}.out", "${file}",
],
"group": {
"kind": "build",
"isDefault": true,
}
},
]
}
重要だと思う部分だけ説明をします
command
実行するコマンドを指定します。ここではg++コマンドでコンパイルするという指定をしています。
args
実行するコマンドに渡す引数を指定しています。
"-g", "-o", "${fileDirname}/${fileBasenameNoExtension}", "${file}"と記述しており、ぱっと見た感じややこしく思うかもしれません。一つづつ説明していきます。また、関連した知識を広げるには以下のサイトが参考になるかもしれません。
-g
コンパイルの際にdebugのための情報を持ったファイルを生成します。この指定がなくてもビルドはできますが、後々プログラムを書くことを考えたら追加しておいたほうがいいでしょう。
-o
コンパイル後のファイルの名前をこちらで指定するためのオプションです。
${fileDirname}/${fileBasenameNoExtension}
コンパイル後のファイル名です。こちらはVSCodeの変数を利用していて、${コンパイル対象のファイルがあるディレクトリ}/${コンパイル対象のファイルの拡張子を取り除いたファイル名}という意味になります。
例えば、hoge/fuga.cppをコンパイルしたらhoge/fugaにしますよーという指定です。
${file}
現在開いているファイル名を表す変数です。コンパイル対象のファイルがここに入るイメージです。
つまり、"-g", "-o", "${fileDirname}/${fileBasenameNoExtension}", "${file}",という指定は、現在開いているファイルをコンパイルして同じディレクトリに拡張子を取り除いたファイル名で配置しますよー。あ、デバッグのためのファイルもつけておきます。という感じでしょうか。
group
こちらはこのタスクをbuildのタスクとしますよーという意味です。
⌘+shift+Bでビルドのタスクを走らせることができるのですが、その時にこのファイルのタスクを実行します。ということです。
このtasks.jsonを保存し、先程のhelloworld.cppを開いて⌘+shift+Bを実行すると同階層にhelloworld.outというファイルができると思います。そいつがコンパイルされたファイルになります。
実行する
後はこのファイルを実行して終了です。
コンパイルはVSCodeのコマンドで行なったのですが、ファイルの実行はターミナルから行いたいと思います。
これは正直個人の趣味です。先程のtasks.jsonにファイルを実行するところまで書いてしまってもいいですが、まあデバッグのためだけにビルドしたい時もあるだろうし、いちいち実行しなくてもいいか。という感じです。
そのうち気が変わるかもしれませんが。
VSCodeでターミナルを開くにはctrl+`で開けます
そこに./helloworld.outと打ち込めばめでたくHello C++ Worldと表示され、終了となります。
Elementインターフェース用にscrollToメソッドを実装する
概要
- クリックなどのイベントをトリガーに、とあるelementをスムーズにスクロールしたい
- Elementインターフェースが持つscrollTopではアニメーションを実装できなかった
- scrollToだとやりたいことができるが、windowインターフェースのプロパティなのでflowtypeがエラーを吐く
- scrollToを自前でelement用に自前で実装した。
課題
クリックなどのイベントをトリガーに、とあるelementをスムーズにスクロールさせたい。そういう時はElementインターフェースに実装されているelement.scrollTopを書き換えるという実装することが多いかと思います。
ただscrollTopの書き換えはsmoothスクロールに対応できず、アニメーション付きでスクロールしていくという要件を満たすことができませんでした。
そこで何かないかと調べてみるとscrollToというメソッドが見つかったのですが、これはwindowインターフェースのプロパティなのでFlowなどの型チェックを行っているとエラーを吐きます。
そして途方に暮れた僕。
解決した方法
githubでコードをあさっていると、scrollToを自前で実装しているコードをちらほら見かけました。 最終的に行き着いた実装方法がこちらです gist.github.com
JedWatson/react-selectのanimatedScrollTo function あたりも参考になるかもしれません。
https://github.com/JedWatson/react-select/blob/2654ce0505d9e3820e169109cc413778fc20f843/src/utils.js#L161
vimのvisualモードで連続でペーストして書き換えられるようにする
vimを使っているとvisualモードで選択してコピーした単語を貼り付けて文字を書き換えるということをすることは多々あると思います。 しかし、設定によっては連続して書き換えようとすると一度目に書き換えられた文字がヤンクされてしまっていて、それをペーストしようとするので同じ文字を連続でペーストできないという問題が発生してしまいます。
例えば以下の文字で、一行目のhogeをヤンクしてfugaとpiyoを書き換えるようにすることを考えます。
hoge fuga piyo
次のようにfugaは問題なく書き換えられます。
hoge hoge piyo
しかし次にpiyoも書き換えようとすると以下のようにfugaがペーストされてしまいます。
hoge hoge fuga
結論を先にいうと、これは.vimrcにxnoremap p "_dPを指定すれば解決します。
解説
では詳細を解説します。
まずこのような問題が発生するのはクリップボードとvimを連携している方だと思います。
vimにはレジスタというものがあります。
試しにvim上で:registersと打ち込むとその一覧が出力され、左側に"0や"*、"%などが表示されると思います。
これはOSがもつクリップボードのようなもので、ヤンクした内容をそれぞれの領域に保存しています。この領域を指定してヤンクすることができますし、もちろんこの領域を指定してペーストすることも出来ます。ググってみるとやり方はすぐに見つかります。
クリップボードと連携した時はブラウザなどで⌘+Cで保存した文字は、vim上では"*の領域に保存され、ペーストする際はデフォルトで"*の領域からペーストするようになります。
とてもベンリで重宝するのですが、visualモードで文字を書き変えた時には、書き変えられた値が"*の領域に保存されてしまうのです。それが原因で先程のような問題が発生してしまうのです。
そこで解決策として、ビジュアルモードでペーストを実行した時にレジスタを"*に保存しないようにするという方法をとります。
それが先程紹介したxnoremap p "_dPです。
ここでは、どこにも保存せず消去するために用意されている消去専用レジスタ"_を利用して、ペースト時レジスタに文字が保存されないようにしています。
これでvisualモードで連続で書き換えられないという問題が解決されるのではないかと思います。
「達人プログラマー」読書メモ
著書達人プログラマーを読んだ。
本書は、より効率的、そして、より生産的なプログラマーになりたいと願う方々のもの
らしい。
読む前にこの本を読んでどういう事を得たいかという問いを立ててから読んだ。 以下3つがその問い
1, 熟達したプログラマーはどんな考え方をしているのか 2, 日々どんなことを意識すればいいのか 3, 優秀なプログラマーとはどんなプログラマーなのか
熟達したプログラマーはどんな考え方をしているのか
直交性やDRYの原則を守ることで、依存性が低く、柔軟性の高いプロダクトを構築する。この考えは単にプロダクトに対するものだけではなく、プロジェクトやチームに広げて考えている。
日々どんなことを意識すればいいのか
自分自身が今何をやっているのか考えつづける必要がある。日々の意思決定、あるいは各開発における全ての意思決定に対して継続的かつ批判的な評価が必要。
優秀なプログラマーとはどんなプログラマーなのか
1, 自分の脳の能力を信じない。1日に使える時間と意思決定は限られており、できるだけ不必要な労力は省き、より高次なものに対して労力をつかう。例えば、データを原材料に自動化や効率化のためスクリプトを生み出し、脳の思考スペースと時間を生み出す。 あと、何かを覚えておくとかもムリ。人間が100%確実にこなせる仕事ではない。
2, 対処不能となる状況や大きすぎるリスクに対する責任を負わない権利を持つ。その責任を負った上で過ちや判断ミスを犯した場合、言い訳ではなくソリューションを提案するべき。
感想
プログラミングを勉強することで論理的な思考が身につく。みたいなことをよく聞くが、 同じように直交性やDRYの原則、自動化などもプログラムの世界だけではなく日常の世界にも広げていくことが達人プログラマーへの入り口な気がした